Preamble
Click below if you’re interested in my journey so far.
Click Here
So the CachyOS experiment from my previous post lasted a grand total of…. 2 days! As great as it is to be on a rolling release with the freshest kernel with the latest packages – it does come with certain caveats. The big deal breaker for me was Docker. Specifically Docker Compose and the NVIDIA Container Toolkit. No matter what I did or what method I used to install each package, I just could not get a container to successfully utilise GPU acceleration. Unfortunately that’s kind of a necessity when working with AI. So off I went, back to a platform I know has worked great for me in the past. Debian! Fedora!
Why not Debian/Ubuntu?
Debian
I use Debian for the majority of my servers and love it, but as a desktop OS it has its limitations, especially for NVIDIA users. Most of the software in the Debian repository is quite dated. Given that I use Plasma 6 as my main DE (at least until Hyprland is more polished), that kind of takes Debian out of the race as it’s still using KDE 5. For Radeon users, this may not be an issue, however NVIDIA REALLY doesn’t play nicely with Wayland/xWayland under KDE. Especially for Electron based applications and some Flatpaks.
Ubuntu
I really don’t like the direction Canonical has taken with Ubuntu in recent years, both with their UI/UX design choices and the inclusion of snap packages as the default choice for application isolation. This review of Ubuntu 22.04 from The Average Linux User pretty accurately reflects my Ubuntu Desktop experience and not much has changed from 22.04 to 24.04. I’ll just say this. There’s a reason Linux Mint Debian Edition exists…
I will note that Ubuntu server on the other hand is pretty stellar.
Other alternatives
While a myriad of distros exist, I seem to consistently find that forks based off the big players end up with minor issues that cascade over time. Documentation can be lacking and community support varies. For this reason I tend to stick with the major players and tweak as needed. Usually Debian for stability, Arch for bleeding edge software, or Fedora for a balance of both. OpenSUSE is another viable alternative.
Requirements
CPU
- A CPU with either:
- A high core count
- Support for AVX512 instruction sets and DDR5*
*Older CPUs and DDR3/4 will work fine for smaller models. AVX512 support is more beneficial to performance than core count IF memory bandwidth allows sufficient data throughput. If budget allows, aim for both.
RAM
- Preferably DDR5. DDR4 and DDR3 will work, but the higher MT/s of DDR5 is beneficial.
- Recommended capacity depends on various factors. Click here to learn more, or use the table below as a rough guide:
| Parameters (b) | RAM (GB) |
|---|---|
| <7b | 8GB* |
| >7b – 14b | ~16GB |
| >14b – 32b | ~32GB |
| >32b – 70b | 64GB+ |
Storage
- ~ 50GB for Docker, Ollama, Open-WebUI and model files
GPU (optional)
- Recommended for enhanced performance. Requirements vary by model and configuration. You can use the chart below as a rough guide for running distilled models:
| Parameters (b) | VRAM (GB) |
|---|---|
| <1.5b | ~1GB |
| >1.5 – 7b | ~4GB |
| >7b – 14b | ~8GB |
| >14 – 32b | ~16GB |
| >32b – 70b | 34GB+ |
Installation
Docker
Install docker engine for your distribution according to Docker Docs instructions
NVIDIA Container Toolkit
NVIDIA Container Toolkit is required for CUDA support.
Fedora
- Add NVIDIA’s Repository
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
- (optional) Enable Experimental Packages
sudo yum-config-manager --enable nvidia-container-toolkit-experimental
- Install the NVIDIA Container Toolkit
sudo yum install -y nvidia-container-toolkit
Debian
Add NVIDIA’s production repository
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
(optional) Enable experimental packages
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
Install the NVIDIA Container Toolkit
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
Arch
Install the NVIDIA Container Toolkit
sudo pacman -S nvidia-container-toolkit
Configure Docker
sudo nvidia-ctk runtime configure --runtime=docker
Restart the Docker Daemon
sudo systemctl restart docker
Ollama + Open-WebUI
Open-WebUI keep a handy Docker Quick Start guide on their GitHub page. There’s a one liner we can use to start an Open-WebUI docker container with Ollama integration.
To add GPU accelaration:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
For CPU only:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
When Docker finishes pulling the images from ghcr, your Open-WebUI instance will be accessible on http://localhost:3000.
Configuration
Click the arrow over “Get Started” when ready.
Enter your name, email and a secure password.
List of newly added features and fixes. Click “Okay, Let’s Go!” when you’re ready.
LLM interactions happen here. First click your initials in the top right.

Select “Admin Panel” from the drop-down menu
Click the settings tab at the top
Click “Connections” in the menu on the left.
1. Click here to view all the models available to Ollama
2. Select a model you are interested in and compare your hardware against the requirements for the distilled version you are interested in. Refer to the table above if you need a rough guide.
2. Enter model name and parameter separated by a colon (e.g. deepseek-r1:14b).
1. Starts a new chat
2. Switches between downloaded models
3. Chat history log
4. Prompt entry field
5. Microphone – voice to text input
6. Call – back and forth interaction with a microphone.
7. Dynamically refine python code by executing within a sandboxed pyodide environment.
8. Prompt suggestions that dynamically adjust based on your prompt.
1. Captures a screenshot from a desktop or application window.
2. Lets you select a file to upload for your model to interact with.
Results
After selecting a model (Deepseek-R1:14b) I ran a quick test prompt to ensure everything works as intended. Deepseek arrived at the correct answer from a mathematical perspective, but incorrect when analyzed logically. 30 is the number of ANIMAL legs, however I asked how many legs do I have? As a human I have two legs. AI’s challenges with trick questions and simple math mistakes can be attributed to several key factors:
- Lack of Real-World Experience: AI systems are trained on datasets without real-world context, making them unable to infer hidden meanings or nuances in language.
- Literal Processing: AI relies on literal interpretations of text, missing wordplay or jokes that humans understand through contextual understanding.
- Training Data Limitations: Simple errors may stem from training data containing inaccuracies or a lack of diverse examples, leading the AI to learn incorrect patterns.
- Focus and Optimisation: AI models might be optimised for complex tasks, neglecting the precision needed for basic arithmetic, resulting in simple calculation mistakes.
- Statistical Approach: AI uses statistical methods that may not perfectly align with the precise logic required for riddles, leading to errors when problems are framed unexpectedly.
In summary, while AI excels at pattern recognition and processing vast data, it struggles with tasks requiring contextual understanding or intricate logical precision beyond its training scope.
Updating Open-WebUI
You can use Watchtower to update your Docker container automatically:
docker run --rm --volume /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --run-once open-webui
If watchtower fails, you can install the update manually in three steps:
- Stop and remove the current container
docker rm -f open-webui
- Pull the latest docker image
docker pull ghcr.io/open-webui/open-webui:main
- Start the container again with the updated image and existing volume attached (add –gpus=all after the -p 3000:8080 parameter for GPU acceleration)
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
Next Steps
What you do with your AI toolkit from here is up to you! There are many many features and integrations you could explore!
For me I aim to do the following
- Integrate my self-hosted search engine with Open-WebUI’s SearxNG integration
- Integrate Ollama with VSCode using Continue.dev’s VS Code Extension
- Compare UnslothAI’s full Deepseek 671B parameter model in it’s 1.58-bit quantized form with Llama.cpp and compare performance against its distilled cousins
- Test various text-to-speek engines to interact more naturally
- Install and test various image generation tools
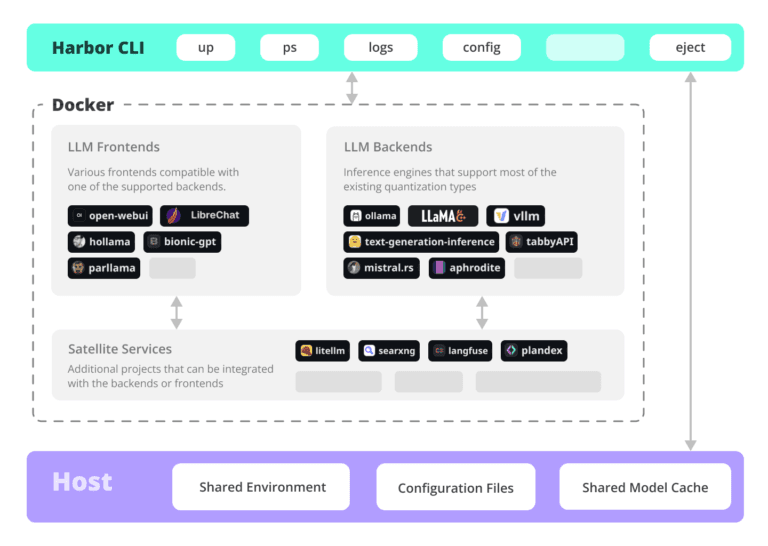
I have found a utility called Harbor that will automate the setup for a lot of these tools. I’ll outline my experience with it in a future post.